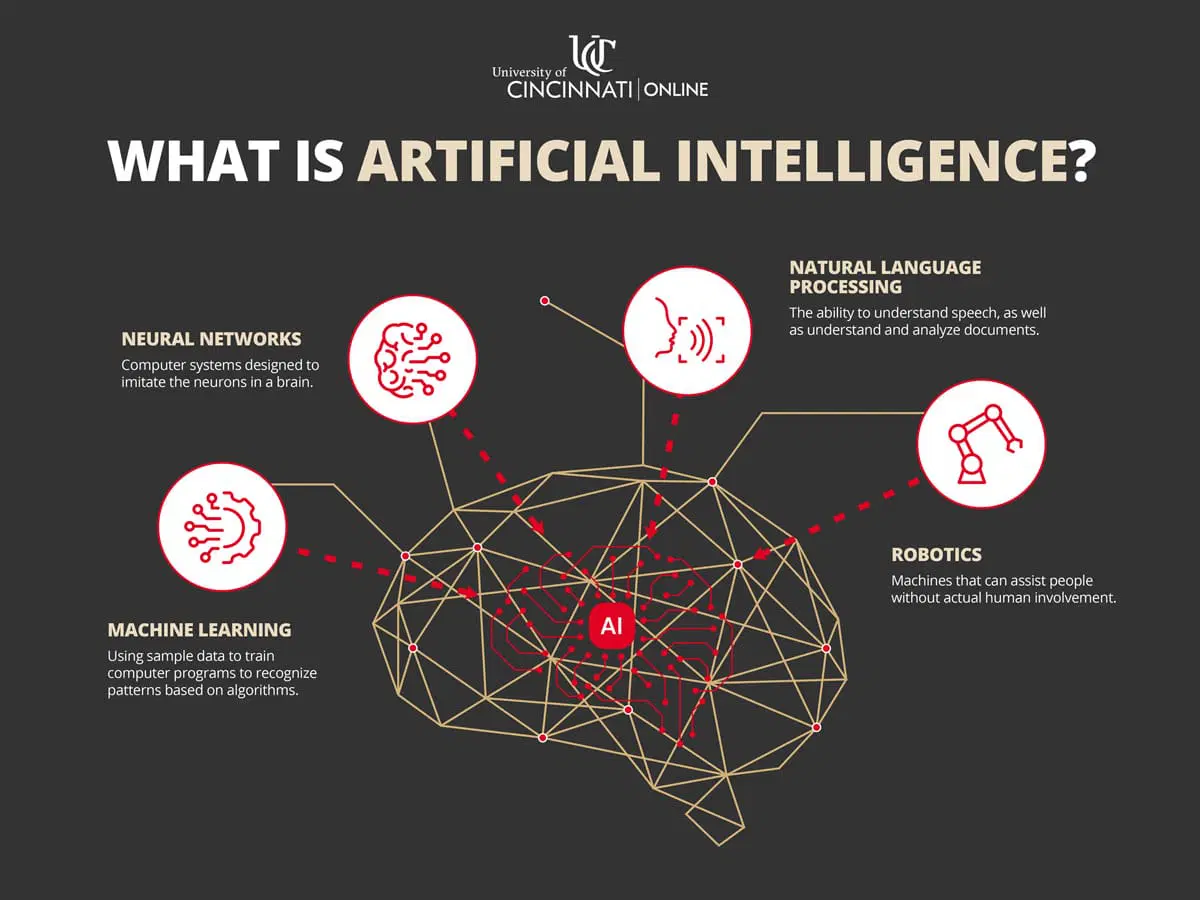
What is AI?
Artificial intelligence (AI) refers to technology that enables computers and machines to simulate human abilities such as learning, comprehension, problem-solving, decision-making, creativity, and autonomy.
AI-equipped applications and devices can:
- See and Identify Objects
- Understand and Respond to Human Language
- Learn from New Information and Experiences
- Make Detailed Recommendations
- Act Independently (e.g., self-driving cars)
As of 2024, the spotlight in AI research and headlines is on generative AI (gen AI), which can create original text, images, videos, and other content. To fully grasp generative AI, it’s essential to understand the foundational technologies it relies on: machine learning (ML) and deep learning.
Machine learning
A simple way to think about AI is as a series of nested or derivative concepts that have emerged over more than 70 years:

Understanding Machine Learning
Machine learning is a branch of AI focused on creating models by training algorithms to make predictions or decisions based on data. It encompasses a wide range of techniques that enable computers to learn from data and make inferences without being explicitly programmed for specific tasks.
There are various types of machine learning algorithms, each suited to different kinds of problems and data. These include:
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Support Vector Machines (SVMs)
- K-Nearest Neighbor (KNN)
- Clustering
One of the most popular types of machine learning algorithms is the neural network (or artificial neural network). Neural networks are modeled after the human brain’s structure and function. They consist of interconnected layers of nodes (similar to neurons) that work together to process and analyze complex data. Neural networks are particularly effective for tasks that involve identifying intricate patterns and relationships in large datasets.
The simplest form of machine learning is supervised learning, which uses labeled datasets to train algorithms to classify data or predict outcomes accurately. In supervised learning, each training example is paired with an output label. The goal is for the model to learn the mapping between inputs and outputs in the training data so it can predict the labels of new, unseen data.
Deep learning
Deep learning is a subset of machine learning that uses multilayered neural networks, called deep neural networks, that more closely simulate the complex decision-making power of the human brain.
Deep neural networks include an input layer, at least three but usually hundreds of hidden layers, and an output layer, unlike neural networks used in classic machine learning models, which usually have only one or two hidden layers.
These multiple layers enable unsupervised learning: they can automate the extraction of features from large, unlabeled and unstructured data sets, and make their own predictions about what the data represents.
Because deep learning doesn’t require human intervention, it enables machine learning at a tremendous scale. It is well suited to natural language processing (NLP), computer vision, and other tasks that involve the fast, accurate identification of complex patterns and relationships in large amounts of data. Some form of deep learning powers most of the artificial intelligence (AI) applications in our lives today.
Deep learning also enables:
- Semi-supervised learning, which combines supervised and unsupervised learning by using both labeled and unlabeled data to train AI models for classification and regression tasks.
- Self-supervised learning, which generates implicit labels from unstructured data, rather than relying on labeled data sets for supervisory signals.
- Reinforcement learning, which learns by trial-and-error and reward functions rather than by extracting information from hidden patterns.
- Transfer learning, in which knowledge gained through one task or data set is used to improve model performance on another related task or different data set.
Generative AI: An Overview
Generative AI, often referred to as “gen AI,” encompasses deep learning models capable of creating complex original content—such as long-form text, high-quality images, realistic video or audio, and more—in response to a user’s prompt or request.
At its core, generative models encode a simplified representation of their training data, drawing from that representation to create new work that is similar, but not identical, to the original data.
While generative models have long been used in statistics to analyze numerical data, the past decade has seen their evolution to analyze and generate more complex data types. This evolution coincided with the development of three advanced deep learning model types:
- Variational Autoencoders (VAEs): Introduced in 2013, VAEs enable models to generate multiple variations of content in response to a prompt or instruction.
- Diffusion Models: First appearing in 2014, these models add “noise” to images until they become unrecognizable, and then remove the noise to generate original images in response to prompts.
- Transformers: Also known as transformer models, these are trained on sequenced data to generate extended sequences of content, such as words in sentences, shapes in an image, frames of a video, or commands in software code. Transformers are the backbone of many leading generative AI tools today, including ChatGPT, GPT-4, Copilot, BERT, Bard, and Midjourney.
How Generative AI Works
Generative AI generally operates in three main phases:
- Training – to create a foundation model.
- Tuning – to adapt the model to a specific application.
- Generation, Evaluation, and Further Tuning – to improve accuracy.
Training
Generative AI begins with a “foundation model,” which is a deep learning model that serves as the basis for various generative AI applications.
The most common foundation models today are large language models (LLMs), created for text generation applications. However, there are also foundation models for image, video, sound, music generation, and multimodal foundation models that support several kinds of content.
To create a foundation model, practitioners train a deep learning algorithm on massive volumes of relevant raw, unstructured, and unlabeled data—such as terabytes or petabytes of text, images, or video from the internet. The training process yields a neural network with billions of parameters—encoded representations of the entities, patterns, and relationships in the data—that can generate content autonomously in response to prompts.
This training process is compute-intensive, time-consuming, and expensive, requiring thousands of clustered graphics processing units (GPUs) and weeks of processing, often costing millions of dollars. Open-source foundation model projects, such as Meta’s Llama-2, enable generative AI developers to avoid this step and its costs.
Tuning
The model must then be tuned for specific content generation tasks, which can be done through various methods, including:
- Fine-Tuning – involves feeding the model application-specific labeled data—questions or prompts the application is likely to receive, and corresponding correct answers in the desired format.
- Reinforcement Learning with Human Feedback (RLHF) – human users evaluate the accuracy or relevance of model outputs so that the model can improve itself. This can be as simple as people typing or talking back corrections to a chatbot or virtual assistant.
Generation, Evaluation, and More Tuning
Developers and users regularly assess the outputs of their generative AI apps and further tune the model, sometimes as frequently as once a week, for greater accuracy or relevance. The foundation model itself is updated much less frequently, perhaps every year or 18 months.
An option for improving a generative AI app’s performance is retrieval augmented generation (RAG), a technique for extending the foundation model to use relevant sources outside of the training data to refine the parameters for greater accuracy or relevance.
Benefits of AI
AI offers numerous benefits across various industries and applications. Some of the most commonly cited benefits include:
- Automation of repetitive tasks
- More and faster insight from data
- Enhanced decision-making
- Fewer human errors
- 24×7 availability
- Reduced physical risks
Automation of Repetitive Tasks
AI can automate routine, repetitive, and often tedious tasks—including digital tasks such as data collection, entry, and preprocessing, as well as physical tasks such as warehouse stock-picking and manufacturing processes. This automation frees workers to focus on higher-value, more creative tasks.
Enhanced Decision-Making
AI enables faster, more accurate predictions and reliable, data-driven decisions. Combined with automation, AI allows businesses to act on opportunities and respond to crises in real-time, without human intervention.
Fewer Human Errors
AI can reduce human errors in various ways, from guiding people through the proper steps of a process to flagging potential errors before they occur, and fully automating processes without human intervention. This is especially important in industries like healthcare, where AI-guided surgical robotics enable consistent precision.
Round-the-Clock Availability and Consistency
AI is always on, available around the clock, and delivers consistent performance every time. Tools such as AI chatbots or virtual assistants can lighten staffing demands for customer service or support. In other applications—such as materials processing or production lines—AI can help maintain consistent work quality and output levels.
Reduced Physical Risk
By automating dangerous work—such as animal control, handling explosives, or performing tasks in deep ocean water, high altitudes, or outer space—AI can eliminate the need to put human workers at risk of injury or worse. Self-driving cars and other vehicles offer the potential to reduce the risk of injury to passengers.
AI Use Cases
AI has many real-world applications across various industries. Here is a small sampling of use cases to illustrate its potential:
- Customer Experience, Service, and Support
- AI-powered chatbots and virtual assistants handle customer inquiries, support tickets, and more, using natural language processing (NLP) and generative AI to understand and respond to customer questions. They enable always-on support, provide faster answers to FAQs, free human agents to focus on higher-level tasks, and give customers faster, more consistent service.
- Fraud Detection
- Machine learning and deep learning algorithms analyze transaction patterns and flag anomalies, such as unusual spending or login locations, indicating fraudulent transactions. This enables organizations to respond more quickly to potential fraud and limit its impact.
- Personalized Marketing
- Retailers, banks, and other customer-facing companies use AI to create personalized customer experiences and marketing campaigns. Based on customer purchase history and behaviors, deep learning algorithms recommend products and services customers are likely to want, and even generate personalized copy and special offers in real-time.
- Human Resources and Recruitment
- AI-driven recruitment platforms streamline hiring by screening resumes, matching candidates with job descriptions, and conducting preliminary interviews using video analysis. These tools can dramatically reduce the administrative workload associated with fielding many candidates, reduce response times and time-to-hire, and improve the candidate experience.
- Application Development and Modernization
- Generative AI code generation tools and automation tools streamline repetitive coding tasks and accelerate the migration and modernization of legacy applications. These tools speed up tasks, ensure code consistency, and reduce errors.
- Predictive Maintenance
- Machine learning models analyze data from sensors, IoT devices, and operational technology (OT) to forecast when maintenance will be required and predict equipment failures before they occur. AI-powered preventive maintenance helps prevent downtime and stay ahead of supply chain issues.
AI Challenges and Risks
Organizations are eager to capitalize on AI’s benefits, but adopting and maintaining AI workflows come with challenges and risks.
Data Risks
AI systems rely on data sets vulnerable to data poisoning, tampering, bias, or cyberattacks leading to data breaches. Organizations can mitigate these risks by protecting data integrity and implementing security throughout the entire AI lifecycle, from development to deployment and post-deployment.
Model Risks
Threat actors can target AI models for theft, reverse engineering, or unauthorized manipulation. Attackers might compromise a model’s integrity by tampering with its architecture, weights, or parameters.
Operational Risks
Models are susceptible to operational risks such as drift, bias, and governance breakdowns. Unaddressed, these risks can lead to system failures and cybersecurity vulnerabilities.
Ethics and Legal Risks
If organizations don’t prioritize safety and ethics, they risk committing privacy violations and producing biased outcomes. For example, biased training data for hiring decisions might reinforce stereotypes and create models that favor certain demographic groups.
AI Ethics and Governance
AI ethics is a multidisciplinary field studying how to optimize AI’s beneficial impact while reducing risks and adverse outcomes. Principles of AI ethics are applied through AI governance systems consisting of guardrails that help ensure AI tools and systems remain safe and ethical.
AI governance encompasses oversight mechanisms that address risks. An ethical approach to AI governance requires involving a range of stakeholders, including developers, users, policymakers, and ethicists, helping to ensure AI systems align with society’s values.
Common values associated with AI ethics and responsible AI include:
- Fairness and Transparency
- Privacy and Security
- Accountability and Responsibility
- Inclusiveness and Accessibility
- Reliability and Safety
History of AI
The concept of a “thinking machine” dates back to ancient Greece. However, significant milestones in the evolution of AI since the advent of electronic computing include:
1950: Alan Turing publishes Computing Machinery and Intelligence, where he asks, “Can machines think?” He proposes the now-famous “Turing Test” to determine if a machine’s response is indistinguishable from a human’s.
1956: John McCarthy coins the term “artificial intelligence” at the first AI conference at Dartmouth College. That year, Allen Newell, J.C. Shaw, and Herbert Simon create the Logic Theorist, the first AI computer program.
1967: Frank Rosenblatt develops the Mark 1 Perceptron, the first computer based on a neural network that learns through trial and error. Marvin Minsky and Seymour Papert later publish Perceptrons, a seminal work on neural networks.
1980: Neural networks using backpropagation algorithms become widely used in AI applications.
1995: Stuart Russell and Peter Norvig publish Artificial Intelligence: A Modern Approach, a leading AI textbook that explores AI’s goals and definitions.
1997: IBM’s Deep Blue defeats world chess champion Garry Kasparov in a chess match and rematch.
2004: John McCarthy publishes What Is Artificial Intelligence?, proposing a widely cited AI definition. The era of big data and cloud computing begins, setting the stage for AI model training.
2011: IBM Watson® defeats Jeopardy! champions Ken Jennings and Brad Rutter. Around this time, data science becomes a popular field.
2015: Baidu’s Minwa supercomputer uses a convolutional neural network to identify and categorize images with greater accuracy than humans.
2016: DeepMind’s AlphaGo, powered by a deep neural network, beats world champion Go player Lee Sedol in a five-game match. Google’s acquisition of DeepMind follows.
2022: Large language models (LLMs), like OpenAI’s ChatGPT, revolutionize AI performance and enterprise value. Generative AI practices enable pretraining of deep-learning models on vast data.
2024: AI trends indicate a continuing renaissance. Multimodal models enhance user experiences by integrating computer vision and NLP capabilities. Smaller models also make significant strides despite diminishing returns in massive models.




